Un LLaMA qui recrache des posts : Notre test de l'IA de Meta
LLaMA (Large Language Model Meta AI) est l'intelligence artificielle développée par Meta. En théorie, pour pouvoir l'utiliser, il faut remplir le formulaire de Meta et attendre sagement que l'équipe de Zuckerberg veuille bien vous accepter dans son club. Mais le 11 mars 2023, une page Web non-officielle, pourvue de liens de téléchargements, est apparue sur la toile. En combinant ces liens et un outil Open Source, il est possible d'installer cette IA sur son ordinateur.
Par Jérémy Pastouret
24 octobre 2023

Pour celles et ceux qui s'attendent à une expérience similaire à ChatGPT, disons-le tout de suite : vous êtes loin du compte. En effet, les équipes d'OpenAI ont particulièrement travaillé l'aspect conversationnel de leur IA, afin que les échanges avec ChatGPT soit les plus fluides possibles. Quitte à faire croire à l'utilisateur·rice qu'elle·il échange avec un·e autre humain·e.
L'IA de Meta, en revanche, cherche à prédire la suite de mots qui vient après notre commande (prompt). Son usage est donc assez surprenant. Surtout qu'en lisant ses réponses, on comprend vite que le jeux de données sur lequel cette IA s'est entrainée est issu de posts Facebook, Instagram (et peut-être même de messages WhatsApp) :
Cette intelligence artificielle créée par Meta pose donc de nombreuses questions éthiques :
- Les posts généré par l'IA sont-ils exactement les mêmes que ceux publiés par leurs auteurs·rices ? Si oui, s'agit-il de posts publics ? Difficile de le savoir à première vue : il faut réaliser davantage de tests.
- Quelles sont les règles posées par Meta pour contrôler son IA ? On l'a vu avec ChatGPT et le mode Dan: les utilisateurs·rices d'intelligence artificielle sont très malin·es pour enlever les barrières de leurs créateurs·rices. Mais contrairement à ChatGPT, l'IA de Meta ne peut pas subir de mise à jour forcée, puisqu'elle s'est retrouvée sur la toile sans contrôle (plus d'infos ci-dessous) avant d'être téléchargée sur les machines personnelles de ses utilisateurs·rices.
- Enfin, est-ce un outil qui pourrait être utilisé pour faire du spam à moindre coût ?
Malgré ces problèmes, on peut espérer que LLaMa permettra à de nombreuses personnes de comprendre à quel point les IA sont énergivores, et exigent énormément de ressources matérielles.
Tout commence par...
Tout est parti d'une demande de modification d'un fichier dans le projetd'intelligence artificielle de Meta.
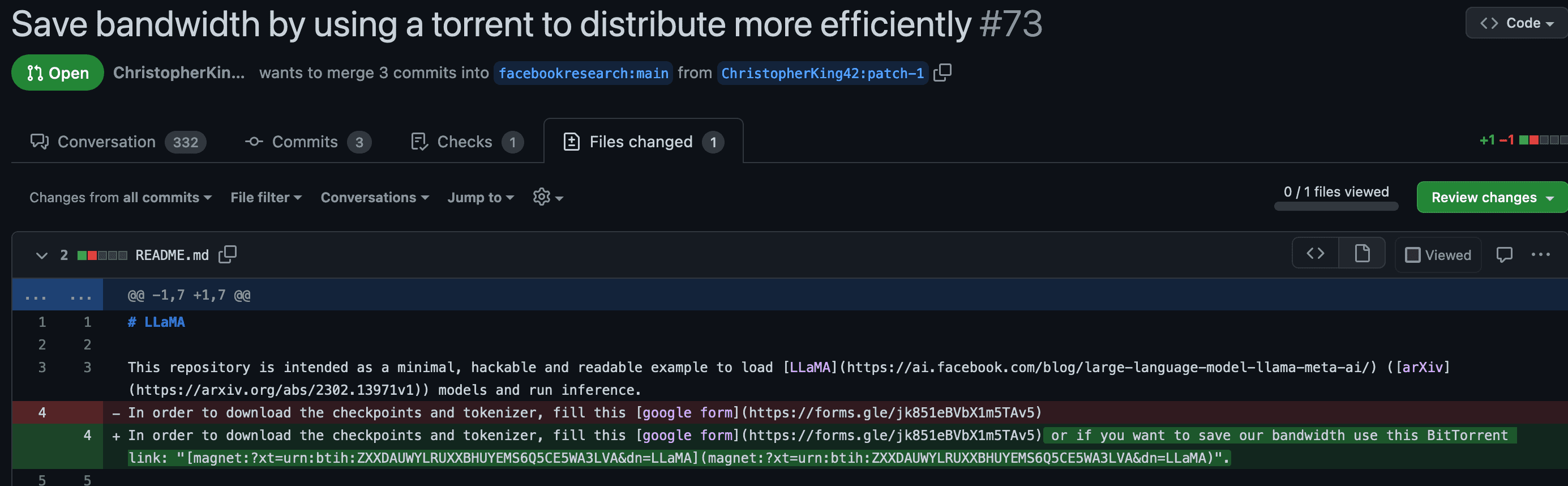
Cette modification proposée par un contributeur contient des liens de téléchargement torrents. Un mode de téléchargement très efficace pour partager des fichiers.
Récap sur les torrents
Ce principe est utilisé depuis longtemps pour télécharger des contenus (jeux, films...) de manière illégale. Les torrents permettent de créer des toiles de téléchargement. Au début, une personne partage un fichier. Une autre personne le récupère, puis le partage également par la suite. Plus le nombre d'utilisateurs·rices possèdant le fichier est grand, plus ce dernier peut être téléchargé rapidement par d'autres internautes. Car le logiciel de téléchargement est en mesure de récupérer partout de petits morceaux de fichiers.
Poids du torrent / IPFS
Pour les plus frileux·ses, le contributeur propose une alternative : télécharger les fichiers en mode Web3 avec IPFS(une variante des torrents plus "jolie", d'un point de vue marketing). Le contributeur ayant publié les liens de téléchargement propose cette solution pour accélérer le téléchargement du modèle. En effet, les fichiers (hackés) de l'IA de Meta pèsent 219Go.
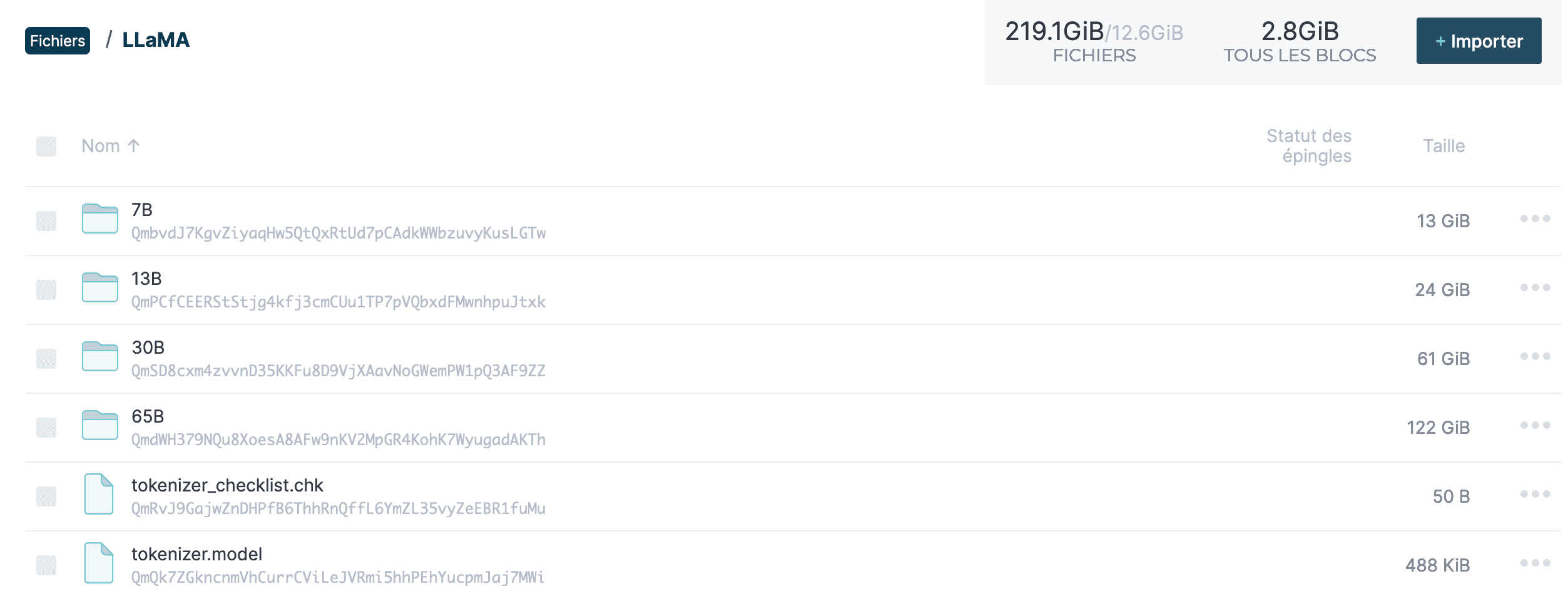
Si vous voulez tester cette IA mais que vous de disposez pas de la fibre, vous pouvez prendre votre mal en patience... car si les fichiers n'ont pas une bonne bande passante, ou si le serveur est lent, cela peut être très long.
Contenu du hack
On y trouve 4 répertoires (7B, 13B, 30B, 65B) correspondant à 4 modèles d'IA différents, classés du moins puissant au plus puissant : de 7 milliards à 65 milliards de paramètres.
Vous remarquerez que le poids des dossiers correspondants est également croissant : de 13Go à 122Go pour le modèle le plus lourd. Il s'agit de fichiers bruts : différentes opérations supplémentaires sont requises par la suite pour les utiliser.
| Nom | Poids | RAM requis | Exemples de carte graphique | RAM / Swap à charger |
|---|---|---|---|---|
| LLaMA - 7B | 3.5GB | 6GB | RTX 1660, 2060, AMD 5700xt, RTX 3050, 3060 | 16GB |
| LLaMA - 13B | 6.5GB | 10GB | AMD 6900xt, RTX 2060 12GB, 3060 12GB, 3080, A2000 | 32GB |
| LLaMA - 30B | 15.8GB | 20GB | RTX 3080 20GB, A4500, A5000, 3090, 4090, 6000, Tesla V100 | 64GB |
| LLaMA - 65B | 31.2GB | 40GB | A100 40GB, 2x3090, 2x4090, A40, RTX A6000, 8000, Titan Ada | 128GB |
Ce tableau issu d'un guidesur le Web (un site ayant depuis disparu, mais néanmoins archivé) indique le minimum de mémoire requise, avec des exemples de cartes graphiques suffisamment puissantes pour gérer les modèles de Meta. Une fois les fichiers traités, le poids des modèles s'allège. Dans le cas du modèle 7B, celui-ci pèse 13Go lors du téléchargement - mais après traitement, son poids passe à 3.5Go.
Après la fuite des modèles de Meta, des guides Web et des projets GitHub sont apparus pour permettre aux développeurs·ses de le tester facilement.
Installation de l'IA
Avant de l'installer, sachez que vous pouvez utiliser une version Web retravaillée par des chercheurs et basée sur l'IA de Meta.
Sinon, le plus simple est d'utiliser un projet nommé dalai, initié par cocktailpeanut (que nous remercions pour sa solution pratique et facile).
⚠️ Attention : le projet concerné lance énormément de lignes de commandes brutes, installe et exécute de nombreux programmes. Nous ne sommes pas responsable des usages que vous en ferez, ni des impacts sur vos machines.
De notre côté, nous avons choisi de l'utiliser pour tester l'IA.
Pré-requis : avoir installé NodeJS
Il suffit de taper la commande (non, ce n'est pas une blague) :
npx dalai llama
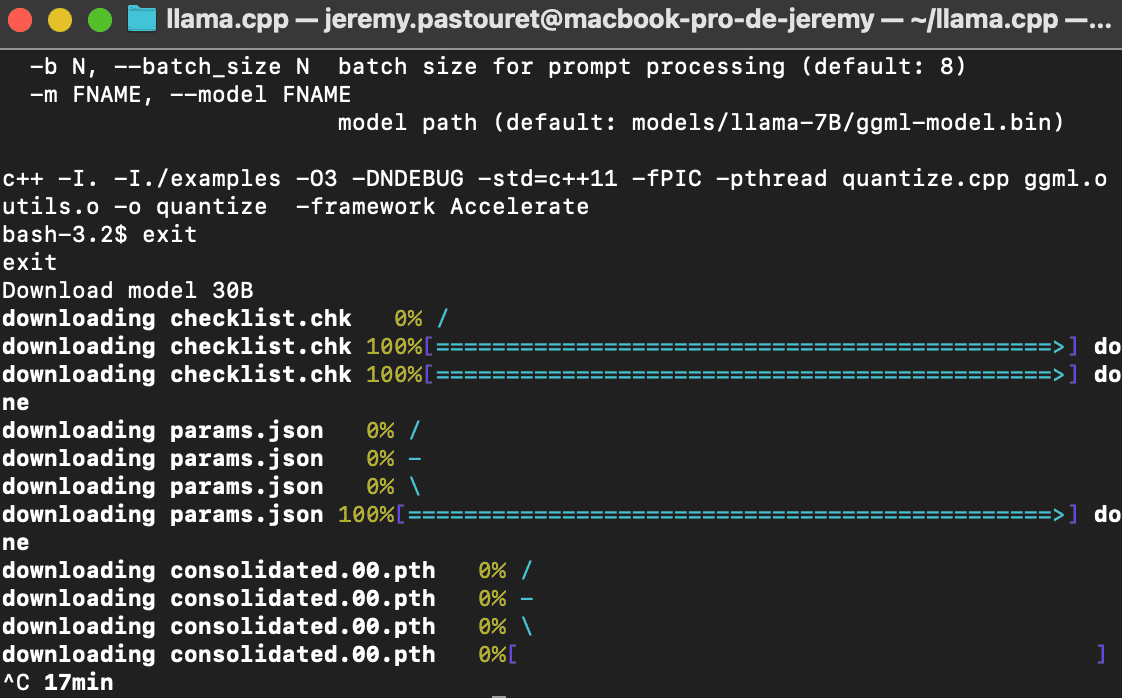
La commande télécharge le modèle le plus léger (7B), puis le traite avec différents programmes afin que votre ordinateur puisse l'utiliser avec son propre processeur ou carte graphique. Nous avons réalisé ce test avec un Macbook Pro M1.
Après l'installation, il suffit de lancer la commande :
npx dalai serve
Une interface web se lance et le tour est joué. La page ressemble à la version test de ChatGPT. Différents paramètres sont ajustables, et en arrière-plan une commande est lancée. Les réponses s'affichent à l'écran au fur et à mesure.
query: {
seed: -1,
threads: 4,
n_predict: 1000,
model: '7B',
top_k: 40,
top_p: 0.9,
temp: 0.8,
repeat_last_n: 64,
repeat_penalty: 1.3,
models: '13B', '7B' ,
prompt: 'ecrit un poeme en français'
}
exec: ./main --seed -1 --threads 4 --n_predict 1000 --model models/7B/ggml-model-q4_0.bin --top_k 40 --top_p 0.9 --temp 0.8 --repeat_last_n 64 --repeat_penalty 1.3 -p "ecrit un poeme en français" in /Users/jeremy.pastouret/llama.cppNous avons également réussi à utiliser la version 13B, soit 13 000 000 000 de paramètres gérables par l'IA. Avec ce modèle, nous avons pu remarquer un bruit de ventilateur croissant et un ordinateur qui commence à bien chauffer.
Avec cette IA, il devient possible de se représenter plus concrètement le coût énergétique et matériel d'un tel outil. Dans un prochain article, nous partagerons nos tests concernant son coût électrique, matériel et environnemental.


